- positionName:职位名称
- link:职位详情页链接
- companyName:公司名称
- city:工作城市
- salary:薪资
- Releasedate:发布日期
- companyType:公司类型
- Field:公司领域
- conmpanySize:公司规模
- JD:职位描述
- address:公司地址
- companyProfile:公司简介
- info:招聘信息 (源于爬取的原因包含了公司地点、工作经验、教育要求、招聘人数、发布时间,以|分隔)
- positionLables:职能类别
- keyword:职位关键字
- positionAdvantage:福利
Excel版,“数据分析岗位”招聘情况分析!|
作者:课课家教育更新于: 2019-05-20 16:03:57
为了练习Excel技能,以及实践数据分析的流程。我用web Scraper爬取了前程无忧4月16日全国发布的约2500条数据分析的职位信息,对数据分析岗位的招聘情况进行简单的分析。整个过程分为五个步骤:明确目的,观察数据,清洗数据,分析过程,得出结论。
01 明确目的
一切数据分析都是以业务为核心目的。本次项目的目的是通过数据分析岗位的招聘信息,包括地区分布、薪资水平、职位要求等,了解最新数据分析岗位的情况。
02 观察数据

首先看一下哪些字段数据可以去除。link为职位详情页链接,是爬取二级页面需要的;Releasedate是职位发布时间,都为4月16日,这两列可以删除。
JD:职位描述、address:公司地址、companyProfile:公司简介、keyword:职位关键字
虽然JD中的职位描述比info中信息更准确,但此次初级分析不对文本进行挖掘,所以先隐藏。尽量不删除数据,而是隐藏,保证原始数据的完整性,以后可能会用到。
03 清洗数据
检查数据缺失:Excel中可以通过选取该列,在屏幕的右下角查看计数,以此判别有无缺失数据,缺失值很大程度上影响分析结果。如果某一字段缺失数据较多(超过50%),分析过程中要考虑是否删除该字段,因为缺失过多就没有业务意义了。
salary、companyType、Field、conmpanySize都存在一小部分的缺失,不影响实际分析。
检查数据是否有脏数据:脏数据包括乱码,错位,重复值,未匹配数据,加密数据等。能影响到分析的都算脏数据,没有一致化也可以算。
数据标准结构:就是将特殊结构的数据进行转换和规整。
我们首先把 city、salary、info拆开。

先将salary拆成最高薪水和最低薪水。比较麻烦的是薪水的表示方式有“XX元/天”,“X-X万/年”,“X-X千/月”,“X-X万/月”,还有空白项。
以天结算的可能是兼职,数量很少直接删除。
空白项是因为岗位链接是公司主页,而不是前程无忧的职位详情页,所以没有爬取到。空白项大概占总量的2%,缺失值可以以业务知识或经验推测填充、可以同一指标的计算结果(均值、中位数、众数等)填充、也可以用回归、贝叶斯形式化方法的基于推理的工具或决策树归纳确定。这里简单采用均值填充。
现在只剩“X-X万/年”,“X-X千/月”,“X-X万/月”三种类型,我打算统一以“X-X千/月”表示。
先用筛选中的“文本筛选”选出所有以“万/年”表示薪资的项:
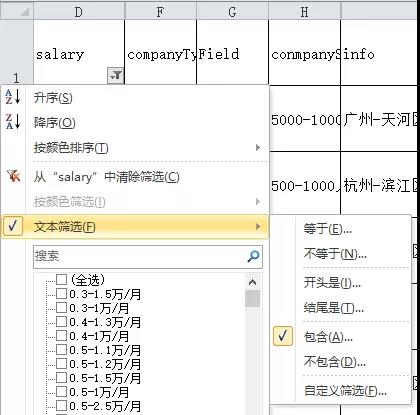
使用分列,以 ‘ - ’ 为分隔符号把salary分为两列,再对最高薪水列使用LEFT和FIND结合,截取单位前的数字:

换算一下单位,取小数点后一位,“X-X万/年”就转变为“X-X千/月”了。
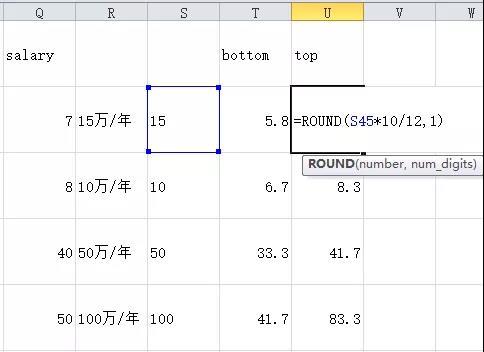
然后筛选出“X-X万/月”的项,同样分列---> 截取最高薪数字--->换算单位:
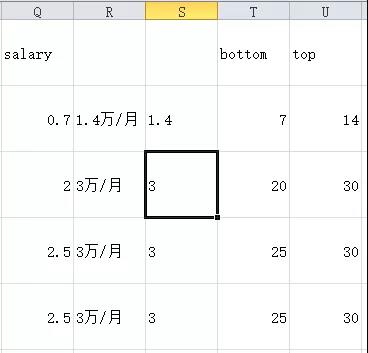
最后筛选出“X-X千/月”的项,分列---> 截取最高薪数字,但不用换算单位了。最后得到的bottom和top列是公式,用复制-->粘贴为“值”,将公式转化为数值。
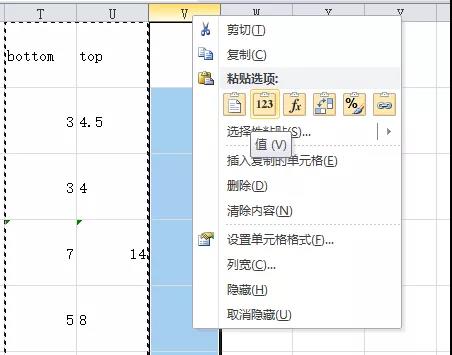
出现了文本与数字交替的情况,

给每个单元格做一次数字运算,全部转换为数字。最后得到统一单位和格式的最高薪水和最低薪水。
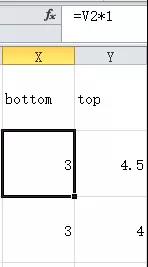
我们简单取最高薪和最低薪的平均数作为该岗位薪资。这是数据来源的缺陷,因为我们并不能知道应聘者实际能拿多少,这是薪水计算的误差。
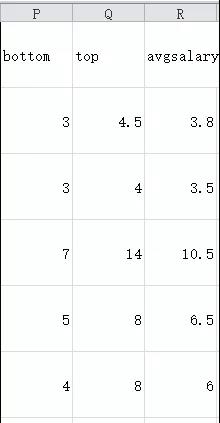
刚才说用均值填充缺失值,均值计算为9.3,对avgsalary为0的项进行填充。薪资项的处理就完成了。
然后是info项,info项的格式类似
以 ‘ | ’ 为分隔符分列,但有的单位在此处填写了学历要求,有的单位没有,而是把学历要求写在JD中。导致education项中有一部分的数据错位为招聘人数。
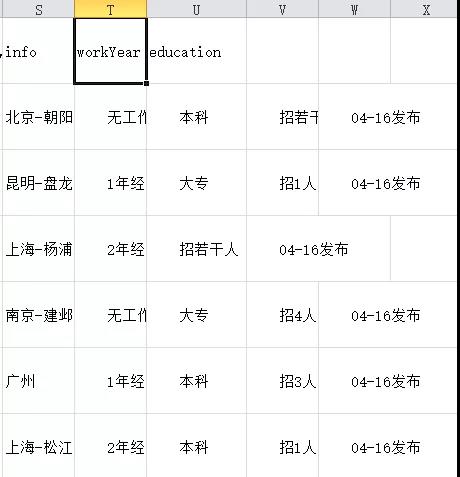
我把薪资小于5千/月的填充为大专要求,小于15千/月的填充为本科要求,大于15千/月的填充为硕士要求,不过这样误差应该会非常大!
然后是city列,用数据透视表统计各城市出现的次数,降序。将小于10个招聘岗位的城市统一归入“其他城市”标签。

数据是否一致化:一致化指的是数据是否有统一的标准或命名。我们看一下表格中的positionName,非常不一致。
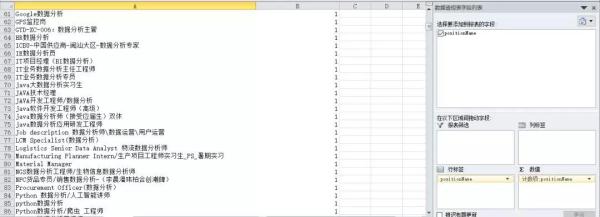
我们需要将数据分析强相关的职位挑选出来,不然会影响分析结果。
用关键词查找的思路,找出包含有数据分析、分析师、数据运营等关键词的岗位,排除掉“品牌专员”、“人力资源总监”、“会计”等非纯数据分析的岗位。用FIND函数和IF函数结合,1为包含,0不包含。将1过滤出来,这就是需要分析的最终数据。

以下是排除掉的岗位,约160个,占总岗位数的6.8%。

04 分析过程
因为主要数据均是文本格式,所以偏向汇总统计的计算。如果数值型的数据比较多,就会涉及到统计、比例等概念。如果有时间类数据,那么还会有趋势、变化的概念。
整体分析使用数据透视表完成,先利用数据透视表获得汇总型统计。
1)工作经验vs岗位数量
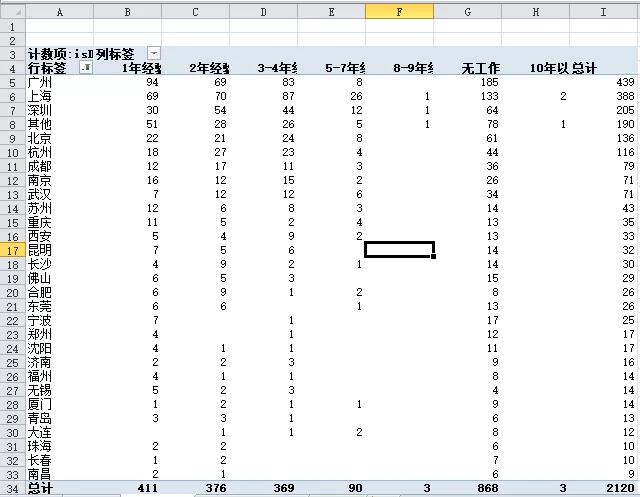
广州和上海的数据分析岗位远多于其他城市。3年以下时间段的缺口更大。无工作经验的应届毕业生似乎比1年以下经验的更吃香。但因为很多公司对学历的要求写在详细的岗位描述中,而不是直接选择的。所以很多显示为无工作经验的岗位,其实在岗位描述中是对工作年限进行了要求的,所以这里的统计很不准确。
2)企业规模vs岗位数量
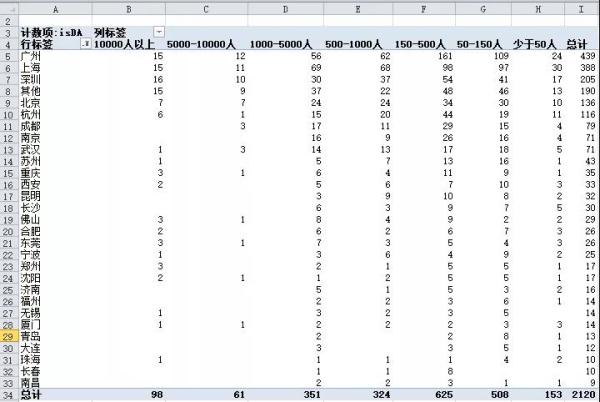
看起来50-150人和150-500人的中小型公司需要的数据分析师更多。
但这样的分析并不准确。因为这只是一个汇总数据,而不是比例数据。如果北京的互联网公司特别多,那么即使有1000多个岗位发布也不算缺口大,如果南京的互联网公司少,即使只招聘30个,也是充满需求的。
还有一种情况是企业刚好招聘满数据分析师,就不发布岗位了,数据包含的只是正在招聘数据分析师的企业,这些都是限制分析的因素。
3)工作经验vs薪资水平
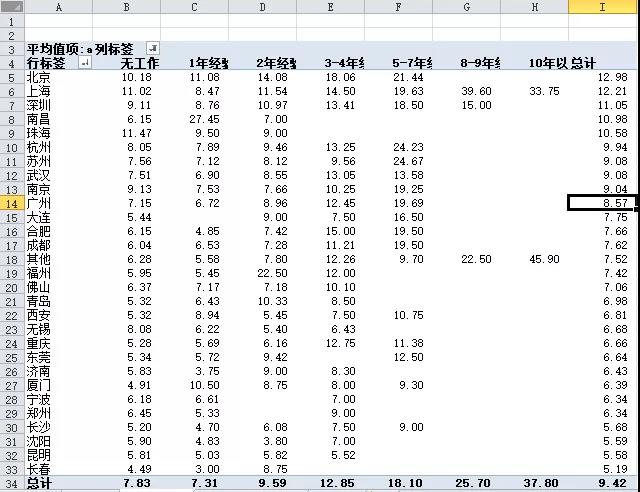
排除不准确的无工作经验项,薪水确实是和工作年限成正比的。
北京、上海、深圳的平均薪资最高,超过10千/月。岗位需求最大的广州平均薪资仅为8.57千/月。
岗位需求量很低的南昌和珠海,因为有个别高薪岗位,所以拉高了平均薪资。

4)使用公司领域标签生成词云图,可以看到对数据分析岗位需求最多的是电子商务和互联网类型的企业。
有各种各样的传统行业,如“服装”“皮革”“纺织”等对数据分析师也有需求。

5)“五险一金”“奖金”“补贴”是公司提到最多的福利。

需要明确:
1、最好的分析,是拿数据分析师们的在职数据,而不是企业招聘数据。
2、承认招聘数据的非客观性,招聘要求与对数据分析师的实际要求是有差异的。
数据的物理结构是数据结构在计算机中的表示(又称映像),它包括数据元素的机内表示和关系的机内表示。由于具体实现的方法有顺序、链接、索引、散列等多种,所以,一种数据结构可表示成一种或多种存储结构。



¥280.00

¥699.00

¥680.00

